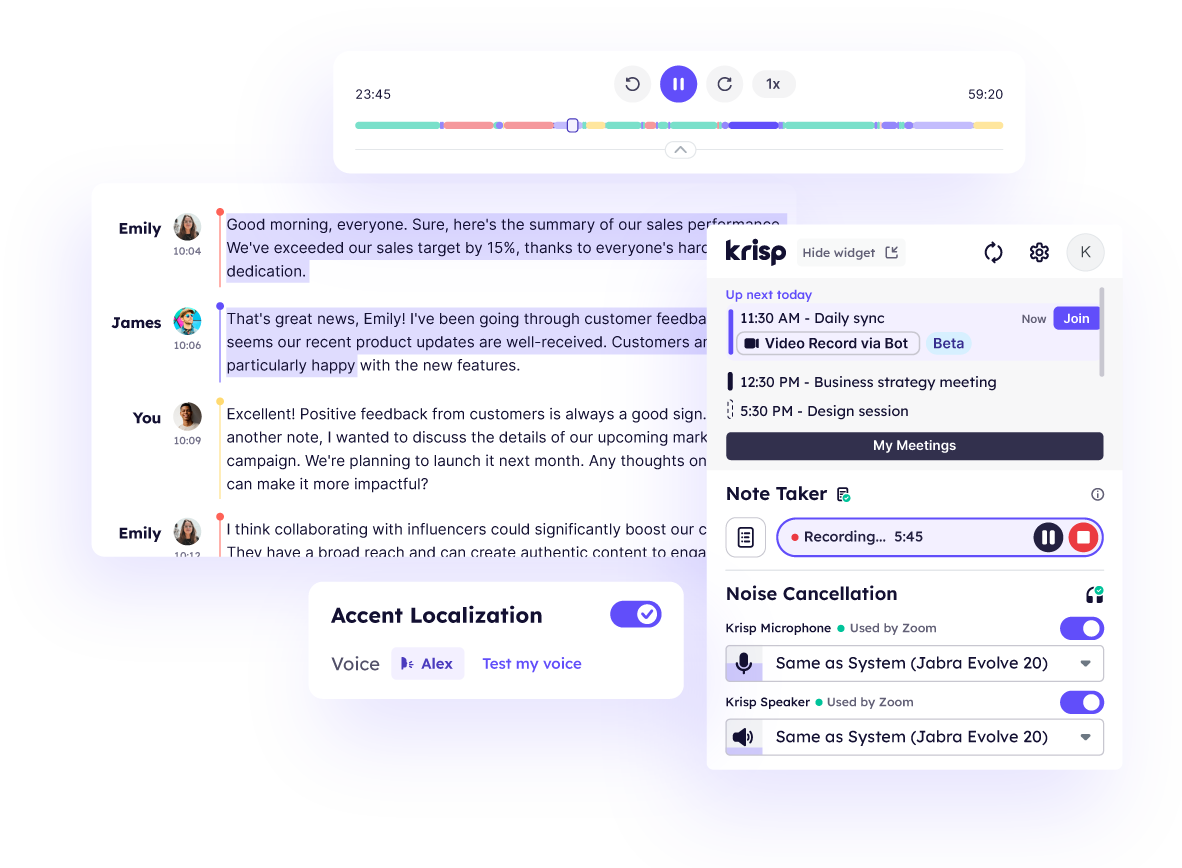
AI Noise Cancellation
Ensure maximum clarity by eliminating background noises, voices and echo from both inbound and outbound meetings and calls.
-
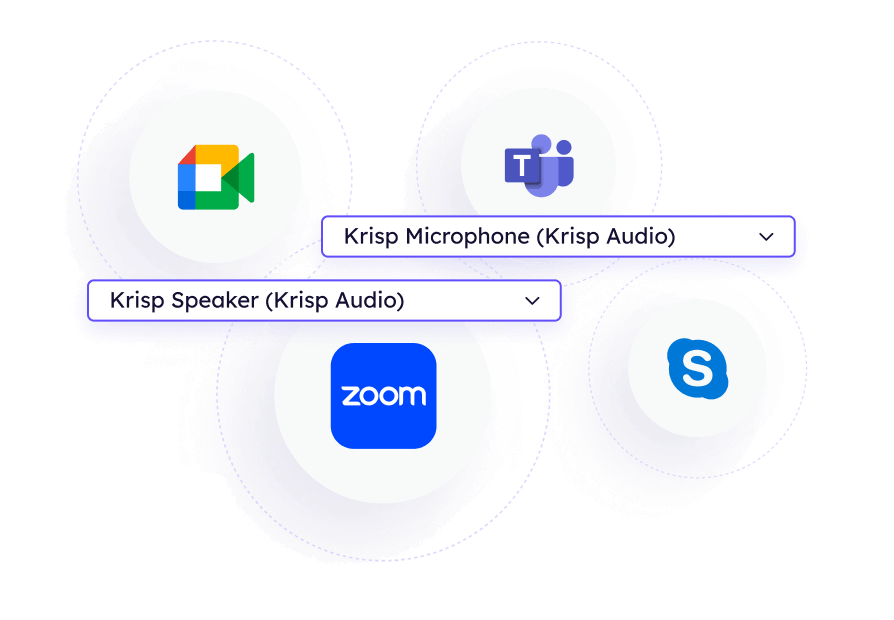
 Works with any conferencing app
Works with any conferencing app
-
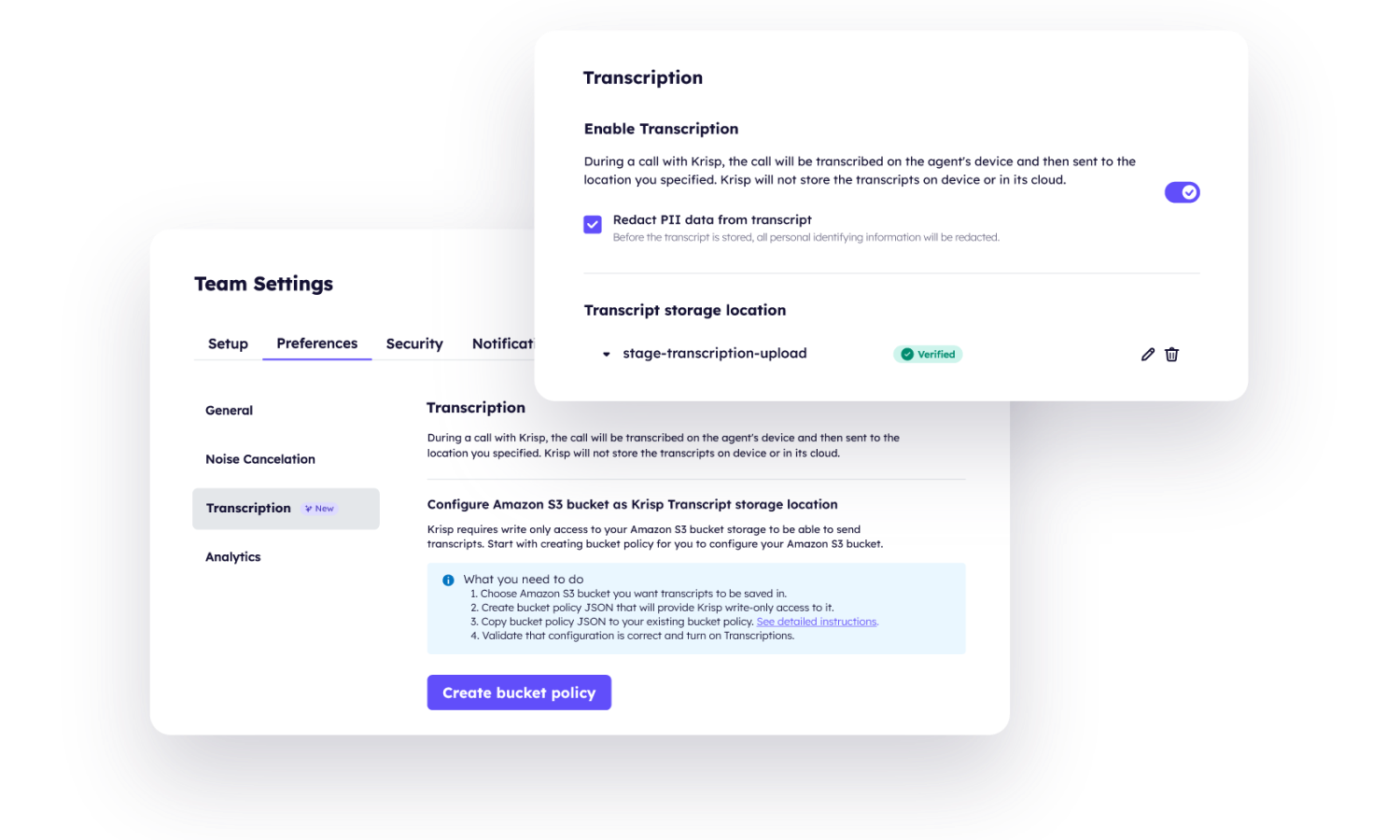
Works with all call center platforms
-
Works with any headphone and device








 Cool Vendor in Digital Workplace
Programs
and Applications
Cool Vendor in Digital Workplace
Programs
and Applications
 America’s Most Promising AI
Companies
America’s Most Promising AI
Companies
 People's Voice Winner in Productivity &
Collaboration
People's Voice Winner in Productivity &
Collaboration
 Leader in Noise Cancellation and Voice
Recognition
Leader in Noise Cancellation and Voice
Recognition





